Cache
Caches take advantage of the locality of reference principle: recently requested data is likely to be requested again.
Caching is the term for storing reusable responses in order to make subsequent requests faster
Advantages
- It has a limited amount of space
- Faster than the original data source
- Contains the most recently accessed items.
Application Server
- Placing a cache directly on a request layer node enables the local storage of response data.
- If your load balancer randomly distributes requests across the nodes, the same request will go to different nodes, thus increasing cache misses.
- Two choices for overcoming this hurdle are global caches and distributed caches.
Distributed Cache
- In a distributed cache, each of its nodes own part of the cached data
- Each node has a small piece of the cache, and will then send a request to another node for the data before going to the origin.
- Therefore, one of the advantages of a distributed cache is the ease by which we can increase the cache space, which can be achieved just by adding nodes to the request pool.
Global Cache
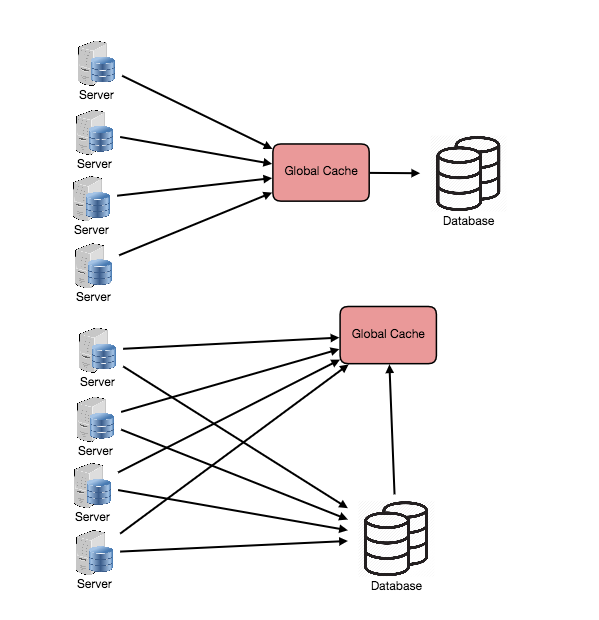
- A global cache is just as it sounds: all the nodes use the same single cache space.
There are two common forms of global caches depicted in the following diagram.
- First, when a cached response is not found in the cache, the cache itself becomes responsible for retrieving the missing piece of data from the underlying store.
- Second, it is the responsibility of request nodes to retrieve any data that is not found in the cache.
Most applications leveraging global caches tend to use the first type, where the cache itself manages eviction and fetching data to prevent a flood of requests for the same data from the clients.
Content Distribution Network (CDN)
- CDNs are a kind of cache that comes into play for sites serving large amounts of static media.
- In a typical CDN setup, a request will first ask the CDN for a piece of static media; the CDN will serve that content if it has it locally available.
- If it isn’t available, the CDN will query the back-end servers for the file and then cache it locally and serve it to the requesting user.
Cache Invalidation
If the data is modified in the database, it should be invalidated in the cache, if not, this can cause inconsistent application behavior.
Cache eviction policies
- Least Recently Used (LRU): Discards the least recently used items first.
- Least Frequently Used (LFU): Counts how often an item is needed. Those that are used least often are discarded first.
With “cache” I always mean in-memory caches like Memcached or Redis. Please never do file-based caching, it makes cloning and auto-scaling of your servers just a pain.
But back to in-memory caches. A cache is a simple key-value store and it should reside as a buffering layer between your application and your data storage. Whenever your application has to read data it should at first try to retrieve the data from your cache. Only if it’s not in the cache should it then try to get the data from the main data source.
Why should you do that?
Because a cache is lightning-fast. It holds every dataset in RAM and requests are handled as fast as technically possible. For example, Redis can do several hundreds of thousands of read operations per second when being hosted on a standard server. Also writes, especially increments, are very, very fast.
There are 2 patterns of caching your data.
1 - Cached Database Queries
That’s still the most commonly used caching pattern. Whenever you do a query to your database, you store the result dataset in cache. A hashed version of your query is the cache key. The next time you run the query, you first check if it is already in the cache.
This pattern has several issues. The main issue is the expiration. It is hard to delete a cached result when you cache a complex query (who has not?). When one piece of data changes (for example a table cell) you need to delete all cached queries who may include that table cell.
2 - Cached Objects
That’s my strong recommendation and I always prefer this pattern. In general, see your data as an object like you already do in your code (classes, instances, etc.). Let your class assemble a dataset from your database and then store the complete instance of the class or the assembed dataset in the cache.
Sounds theoretical, I know, but just look how you normally code. You have, for example, a class called “Product” which has a property called “data”. It is an array containing prices, texts, pictures, and customer reviews of your product. The property “data” is filled by several methods in the class doing several database requests which are hard to cache, since many things relate to each other.
Now, do the following: when your class has finished the “assembling” of the data array, directly store the data array, or better yet the complete instance of the class, in the cache! This allows you to easily get rid of the object whenever something did change and makes the overall operation of your code faster and more logical.
And the best part: it makes asynchronous processing possible! Just imagine an army of worker servers who assemble your objects for you! The application just consumes the latest cached object and nearly never touches the databases anymore!
Some ideas of objects to cache: user sessions (never use the database!) fully rendered blog articles activity streams user<->friend relationships